
Technical
Developing a Deployment System
Naphat Sanguansin

Deployment is at the heart of the engineering process. From my experience working on teams of 3 to an organization of 1000, this has held in all environments.
Why is this the case?
A practical and robust deployment system enables engineers to ship code faster, more reliably, and spend time on their core competencies instead of debugging infrastructure. Having an ineffective deployment system results in inefficient engineers and unhappy customers.
We previously wrote a blog about what the experience of a deployment system built for cloud-native and distributed systems would feel like. However, what should the technical architecture of such a deployment system look like?
For the rest of the post, I’ve written this in the format I typically use for design docs.
Goal
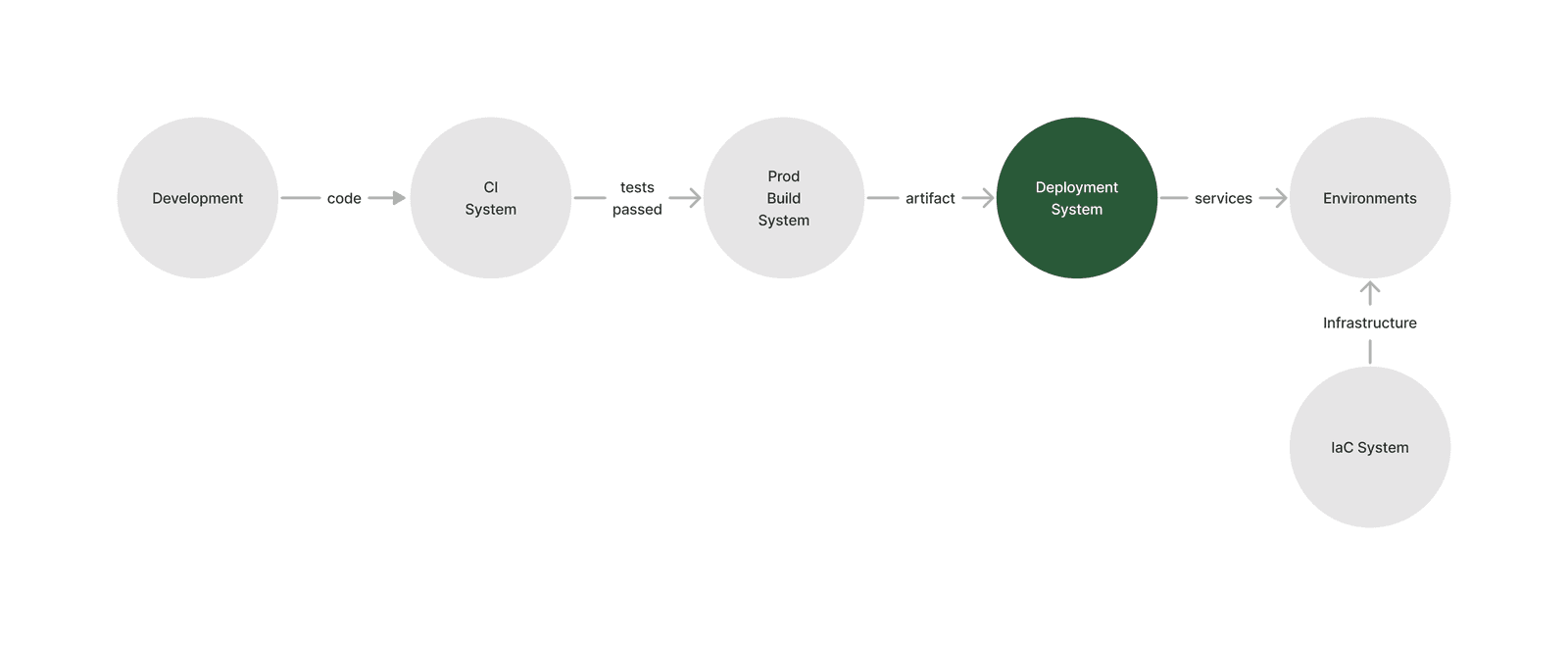
The goal of a software deployment system is to ensure that the correct production artifacts (e.g. docker image + service) are in the proper environments at any given time.
A deployment system sits between the production build system (sometimes part of the CI system) and the production environments. It is separate from IaC (e.g. Terraform and whatever is running it). IaC provides infrastructure, such as a Kubernetes cluster and databases, while a deployment system ships application code to that infrastructure.
Architecture
A deployment system can be broken down into these core components.
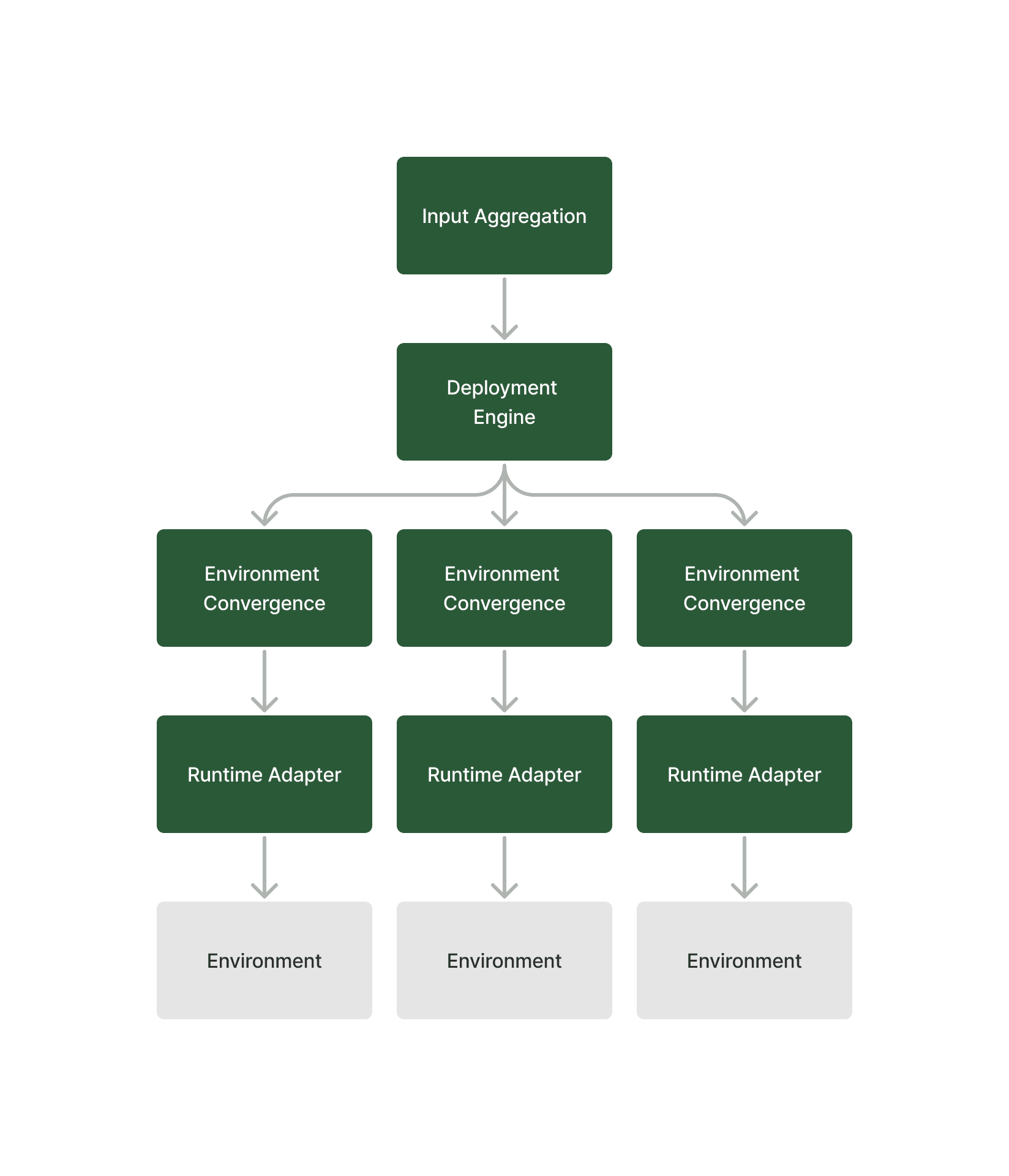
Input Aggregation
A deployment system needs at least the following inputs to do its job:
List of environments to deploy to and their ordering
Service configuration, potentially per environment
Additional deployment guardrails and where they fit (e.g. manual approvals, automated testing, alert checks)
The deployment artifact (e.g. docker image)
These inputs often come from multiple stakeholders in the organization, including but not limited to:
The service owner
Platform/DevOps/Infrastructure Engineering
Finance
Security/Compliance
Product managers/Business owners

A deployment system must aggregate these inputs to make decisions and compile them to a single desired state.
The Deployment Engine

The deployment engine is responsible for deciding the next step in deployment.
The deployment engine takes inputs from the input aggregation component and the actual state of production environments to make critical and best deployment decisions.
When working optimally, it should be able to handle a simple deploy X after Y use case, as well as the following use cases:
If production has errors during deployment → halt the deployment/rollback
Wait for a resource (e.g. database migration) to exist/be updated before deploying. Optional: notify the team responsible for said resource
Wait for human input before deploying
Environment Convergence

Once the deployment system decides a service in an environment should be at a particular version, it must ensure it is at the desired state.
This layer can be replaced with a one-off push task should the environments be static. Unfortunately, environments are rarely static.
For example: what if a cluster temporarily disconnects from the deployment system, only to return online later?
Convergence ensures that live clusters are running the correct version of code. Stale code is, at best, confusing to engineers and, at worst, downright dangerous.
Additionally, changes in production can come from multiple sources, not just a push.
What happens if a new cluster needs to be spun up?
This can be part of everyday operations (e.g. a single-tenant SaaS app) or a critical operation (e.g. upgrading a k8s cluster by spinning up a new cluster). Convergence and input aggregation make infrastructure changes a non-event that does not require a push to all services across all environments. Without convergence, a cluster spin-up requires all service owners to be involved and can take months (yes, I am speaking from personal experience).
Runtime Adapter
After all the above steps, the deployment system needs to deploy. The runtime adapter translates logical intent into infrastructure operations.
Some deployment systems are built only for a single runtime, e.g. k8s, and entirely bypass the need for this component. Many organizations, unfortunately, must deal with multiple runtimes, e.g. static assets, lambdas, and legacy systems.

The runtime adapter is as complicated as all the other components combined. It must have an interface that allows adding runtime types without increasing the complexity of other elements.
Security is also an important aspect. A deployment system must talk to all environments, including staging and actual production, without exposing production to attacks from staging. Securing the runtime adapter is and will be another topic in itself!
The High Cost of Turning Primitives Into A Deployment System
If, at this point, you find yourself thinking, “this looks like a fairly complicated distributed system,” you’d be right.
Many teams start primitively, reusing CI for deployment and only handling services that are changed often. As organizations grow, these primitive systems break down. Common turning points include creating a new environment and allowing other non-infrastructure teams to deploy. In my experience, deployment quickly becomes an entire team of 5+ engineers.
Previously, we have blogged about the ineffectiveness of existing 3rd party CD systems today. These systems are missing at least one of the critical technical components above, wasting too much time and resources with in-house building. Examples where these systems fail:
CI-based solutions only handle the engine component but not particularly well since they don’t react to production changes.
Even if one manages to run all of its projects, Argo does not handle input aggregation well. It relies on a pipeline-based solution for cross-environment coordination and only works on Kubernetes natively.
Helm + Argo or a CI system requires building and maintaining the Helm templates and restricts you to working only on Kubernetes.
Spinnaker is complicated to set up, annoyingly hard to debug and does not handle environment changes such as a cluster spin-up well.
Inevitably, teams pick one of these solutions and build significant components around them. Hiring an entire team to maintain the cobbled-together and ultimately primitive system.
Prodvana Can Help
Prodvana is an end-to-end, opinionated SaaS deployment system for distributed systems and cloud-native applications. If you find yourself writing a design doc similar to this one, designing any of the components above, or experiencing any of the challenges outlined, I’d love to talk.
Book some time with me to chat!






