
Technical
Deployment Complexity in Distributed Systems (Part 2 of 2)
Anup Chenthamarakshan
In distributed systems, teams often struggle between deploying safely and working efficiently.
As Andrew Fong, CEO of Prodvana, wrote, distributed systems create extreme complexity in pipeline-based deployments. In this post, I share my real-life experience in pipeline-based deployments with distributed systems. My background has been focused on building at-scale CI/CD and production storage systems at Google and Dropbox.
Complex Storage Deployments
Before Prodvana, the last role I had was on a team of 8-10 engineers supporting 15 - 20 services of a storage backend that supports 100s of millions of users. Several of these services directly touched customers, so we pushed slowly and carefully. Stability was critical.
When I started on this team, each service had varying deployment processes. Most operations were manual, with very long playbooks that had to be followed step by step, taking over 24 hours. Pushes were weekly on services. No engineer had expertise in debugging all of the services, so we all had to get involved during deployments and debugging operations.
Every weekly push caused a mini-outage and needed babysitting.
Oncall rotation became a full-time responsibility with no real work happening during this time. Weekly mini-outages became the norm, impacting the entire team’s efficiency.
Why were we experiencing so many problems?
Deployments were just too complex.
Typically, each deployment pipeline supported a small group of services that would go out at a fixed cadence (weekly, daily, etc.). The deployment was coordinated across all services in its group. The pipelines were extremely complex to ensure safe deployments.
A pipeline ran 24 hours at a minimum with a push to the staging environment, a canary, and then fully out to production process at the very least.
When something failed, that service could be rolled back, but none of its sibling services would automatically roll back with it. If the failure was critical enough, we had to manually roll back all the other services to keep them synchronized. There was no real option to fix something mid-rollout. Our only options were to roll back to the beginning and restart.
The deployment system was designed for the happy path. It would have been impossible to map all failure states in a pipeline because of the sheer volume of permutations across 20 services.
Over time, my team improved our situation by standardizing the deployment process for all our services. We settled on: stage, canary 1%, canary 10%, then 100% to production as our pipeline standard. We also standardized alert metrics for each service (p99/p99.9 latency and error rate threshold), produced templates for alerting, and aggressively burned down causes of alerts and noisy logs.
It took many months to work through to get these changes as the standard set of pipelines.
How this works with Prodvana
If we were to rebuild this on Prodvana today, we would have had to do the following:
Declare our environments
Declare our outcomes
Declare our application requirements
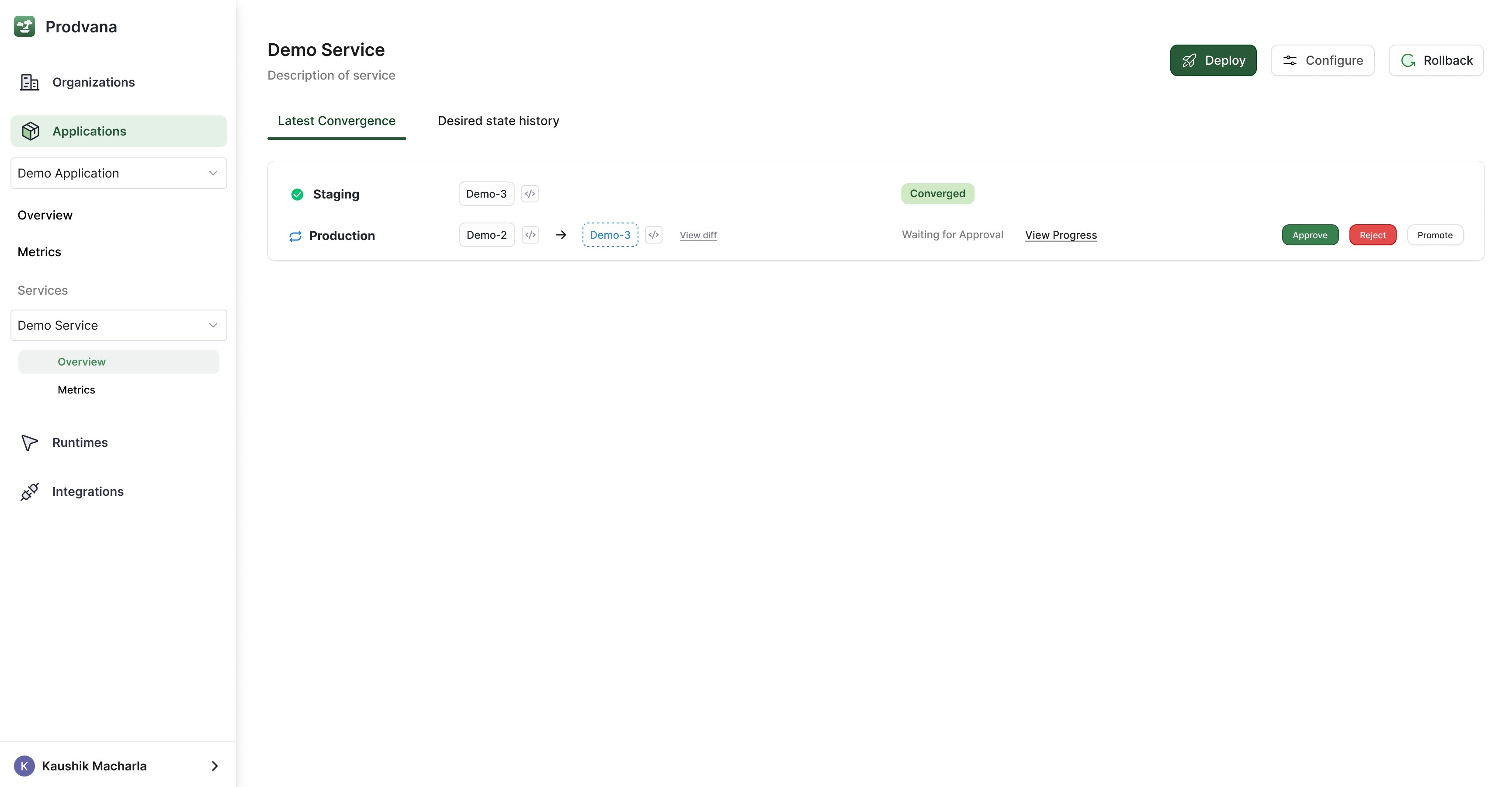
The following view allows the operators to understand at altitude what flows are occurring and the dependencies without being concerned about how the path is being charted every time.
In this view, we can see where in the convergence we are. Staging has been converged safely, and we are awaiting manual approval to move to production.
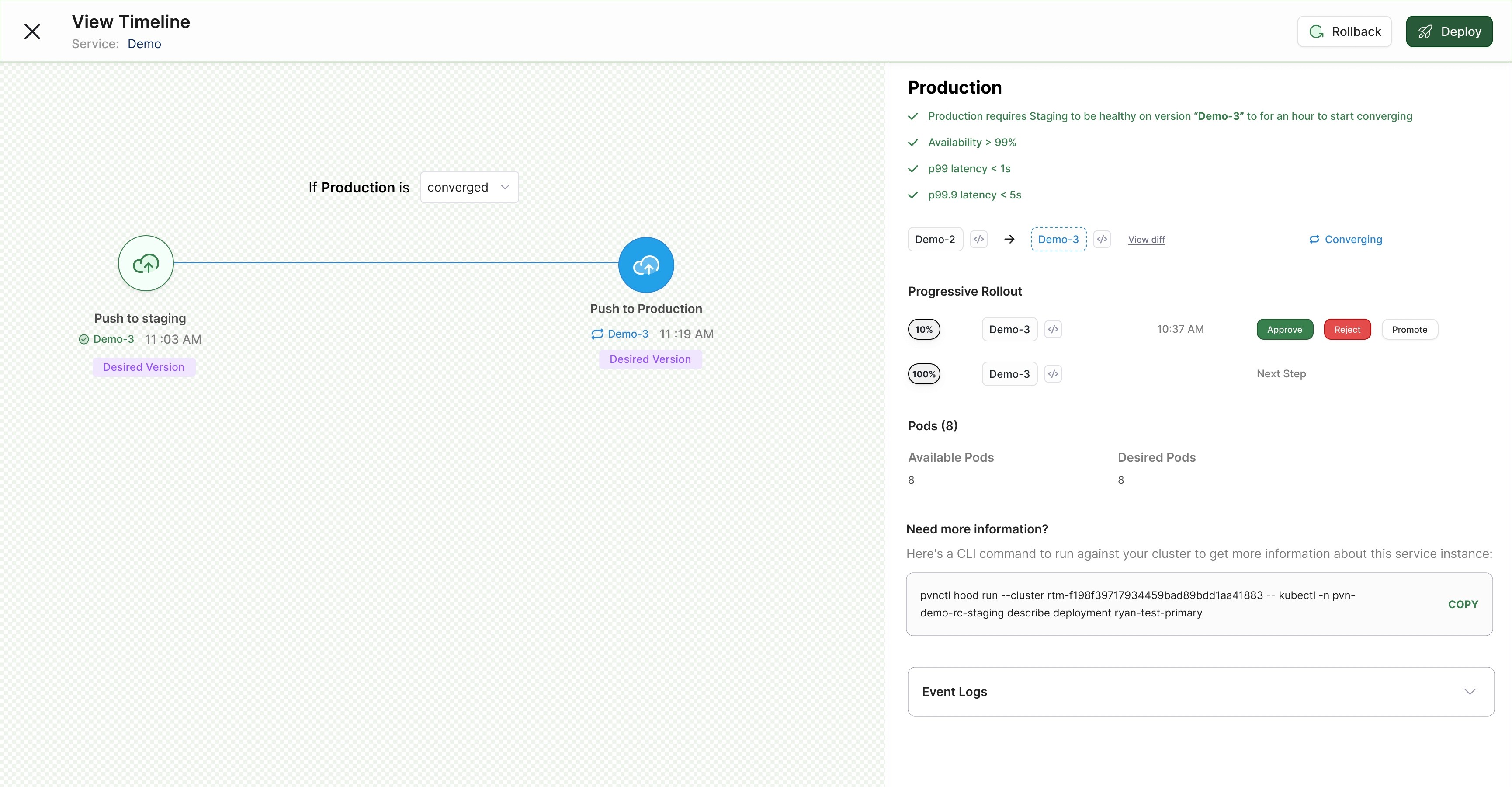
As we dig deeper into Prodvana, it's clear that production has a set of requirements to meet before it can start converging to the desired state. Those can be seen in the upper right with green check marks. Below are the progressive delivery steps that will be taken for production and how to get information about production if you need to debug further.
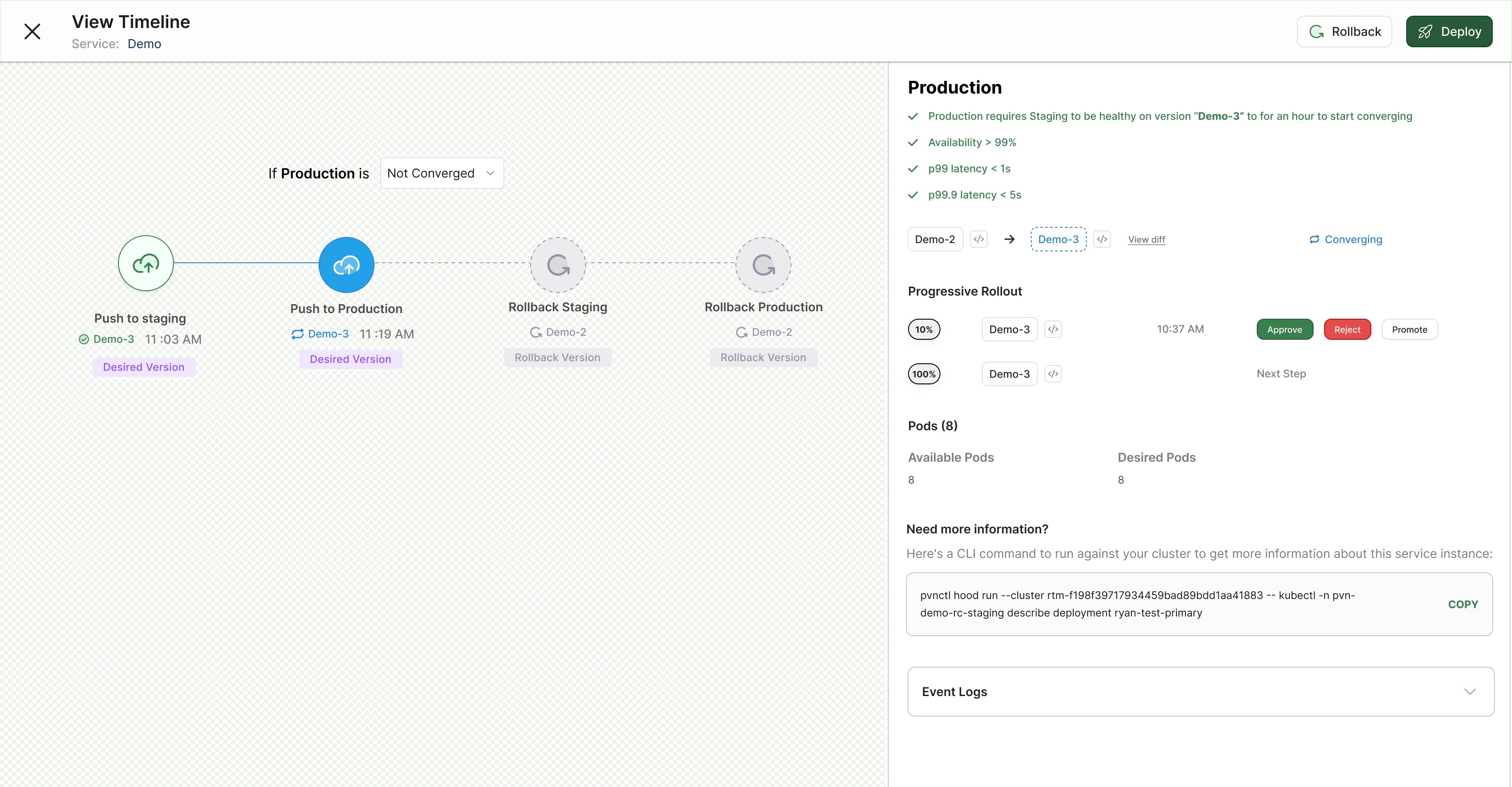
In this last view, you can see what will happen if production does not converge to the desired state. The rollbacks will progress in that order. This gives you a clear view of what future states can be during deployment as well. All of this is to demystify what will happen to engineers who may not be familiar with the system as the original owner systems.
Are you facing similar challenges in your distributed systems? At Prodvana, we’re working to solve these problems for you. Book a demo with us to find out how Prodvana can help.






