
Industry Thoughts
Imperative configs are out; Declarative configs are in.
Naphat Sanguanasin

Have you ever had to look up directions to meet a friend? Then memorized it or written it down? Only to find a roadblock, accident, electrical issues on the tracks, and many other unforeseeable issues. Whatever the mode of transportation - train, driving, bus, walking, biking, we’ve all been there.
In 2012, my dad flew from Thailand to New Jersey to visit me during my freshman year of college. To prepare for driving and getting around in the US, he did a large amount of research, mapped out the routes he would take, and even printed the directions out in advance from Google Maps for his entire week-long trip. You can imagine what happened next.
My dad got lost multiple times just getting from JFK to Princeton’s campus. All the prep work he had done upfront could not prepare him for the unknowns of the real world, from confusing exit signs, windy roads, and, unlabeled side roads.
Google Maps launched turn-by-turn navigation in 2012. So when he finally got to Princeton, I showed him the power of turn-by-turn directions and how Google Maps would recalculate automatically.
Declarative vs. Imperative
My dad switched from working with a map printout without knowing real-time conditions, the imperative flow, to Google Maps with turn-by-turn directions, the declarative flow. This completely changed how he traveled. It gave him the confidence to travel into unknown areas without significant prep work.
The insight that declarative flows make life easier for the user is hardly new. We use them in many other parts of our lives -- from stock portfolio optimization, retirement planning, fitness goals with meal prep, autocomplete text, and more. Yet, software delivery is still rooted in the imperative flow today.
Current continuous delivery systems require engineers to define steps upfront, similar to how my dad had to print out directions driving from JFK to Princeton. With CD systems today, engineers are forced to prioritize the “How” of delivery and not the “What.”
CD systems ask you to codify the pipeline statically because they assume static environments. Real-world cloud environments are anything but static. Just as my dad got lost going from JFK to Princeton using paper maps, static pipelines will ultimately fail to deliver the outcome you want in a timely and optimal manner. This is because the fundamental premise of “being static” that CD systems are built on is broken in a cloud-native world. It is a relic from waterfall SDLC and GoldMaster compact disc printing.
After reading this, you might be thinking, “Aren’t most CD systems declarative?”
Many CD systems claim to be declarative. For example, Argo CD brands itself as the “Declarative GitOps CD for Kubernetes.” Harness touts “declarative GitOps and powerful, easy-to-use pipelines” on its CD product page. Unfortunately, these systems are declarative about the pipeline, not the delivery.
For example, while Argo CD is declarative within a single environment, it needs to be paired with the imperative Argo Workflows to coordinate delivery across environments. In all cases, the engineers are still forced to think about the “How” and not the “What."
The remainder of this blog will walk through a real-world, concrete technical example of how the imperative flow struggles to deliver software to its full potential.
A Concrete Technical Example
To see how imperative workflows fall apart, let’s walk through a real example.
In this example, there are two environments: staging and production. You want to deploy code to staging, wait one hour, validate, and then deploy to production.
A traditional CD product (Tekton, GitHub Actions, Argo Workflows, CircleCI) will require you to define a pipeline like:

As you mature, you will start to add more to the configuration. Typical advances include automatically validating the health of the environment.

In this case, `wait` task was replaced with `check_alerts` task on staging.
This encounters two big issues with imperative pipelines
Ordering - What if the alert fires during the staging push, before the `check_alerts` task runs, or right after `check_alerts`?
Imperative pipelines are modeling a set of steps. Alerts, push tasks, and conditionals show up as equally important, causing your original intent to be lost.
Alerts are powerful, but automation is how you get a full night’s sleep. This is if the system knows and performs the right action based on the failure. In this specific case, we want to rollback the configuration to this point:

NOTE: The config has now more than doubled in line count, making it impossible to remember the original intent of the configuration.
As we continue to evolve our environments, we now add beta, which should be deployed between staging and production. Code is shown below:

The configuration has become so complicated that it does not fit vertically on a 4k monitor. It is also incredibly error-prone.
I purposely introduced an error above - can you find it?
OPPORTUNITY: For the first 25 people that find the error and book a demo, you’ll receive a $50 Amazon Gift Card!
Declare It
Rewriting the above stages declaratively makes the code much simpler without losing sight of the outcome. Starting from the base case - define the outcome:
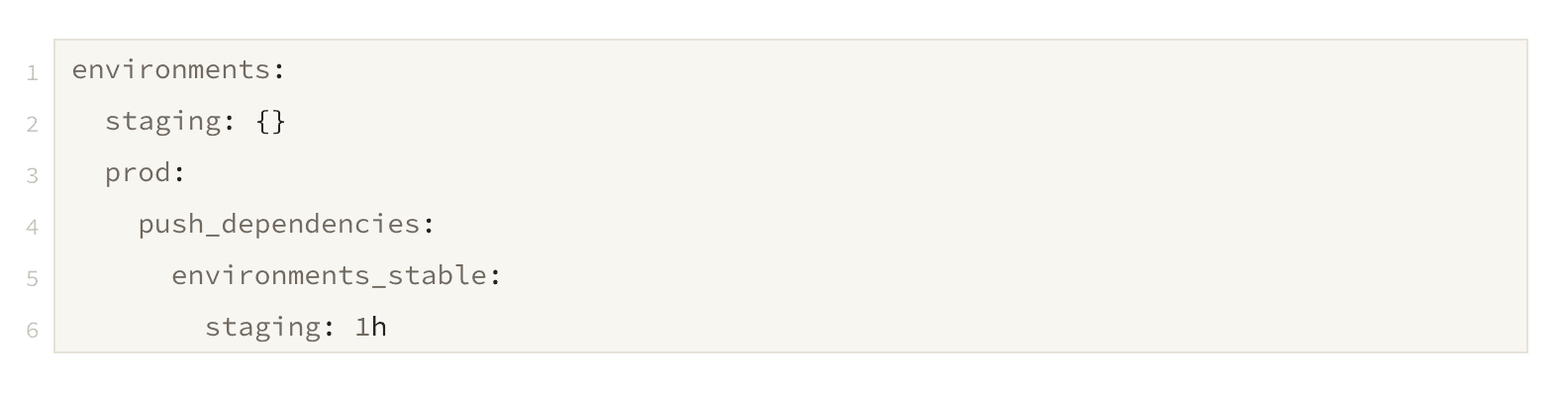
Notice that there is no pipeline being defined. An intelligent delivery system uses this configuration to deliver your intention: the outcome.
Juxtapose this with an imperative system where the pipeline is your intention. Therefore, the system cannot adapt.
The rest of the configuration following the above looks like this:
Alert Checks

Adding Auto Rollbacks

Adding Beta environment

Enabling a New Class of Delivery Systems
Declarative configurations free up the delivery system to make intelligent choices and enable user workflows that seemed too hard or impossible in an imperative system. Let’s take the simple case of retries.
In the real world of production, things rarely work exactly as planned. Maybe an alert goes off and turns out to be a red herring. This red herring causes a push to fail between staging and prod. What happens in a traditional CD system?
If a pipeline fails halfway, most CD systems don’t have the ability to retry. The only option is to restart a pipeline from the very beginning. Now with declarative configs, an intelligent delivery system, the system will detect that staging is already on the desired version and skip that push, allowing you to deliver value to your customers faster.
Another example is skipping environments in a push. Take the scenario from the previous section. Skipping staging here isn’t just skipping the push to staging step, but it is also skipping the alert checks on staging and any staging rollbacks. An intelligent delivery system will be able to take the declarative config and trivially allow skipping of staging, where most CD systems do not support skipping out of the box.
These are just two of the many ways that an intelligent delivery system can take advantage of declarative configuration. Our mental model of delivery is so tightly coupled to static pipelines that we do not even consider the powerful alternatives that exist.
A significantly more powerful & robust delivery workflow has emerged by coupling declarative configuration with an intelligent delivery system.
Just as Google Maps gives you turn-by-turn directions adjusting based on current conditions, Prodvana’s Dynamic Delivery Platform gives you the power of real-time pipelines. Dynamic Delivery will substantially reduce overhead, and like my dad with paper maps, you’ll never want to go back to static pipelines again.






