
Feature Release
Introducing Clairvoyance: Your Personal Spidey Sense
Andrew Fong

I have been an SRE, Manager, VP, and CTO at AOL, YouTube, Dropbox, and Vise where I carried the pager as a primary, escalation and, escalation of last resort.
I have deployed countless changes, dealt with innumerable incidents, and forgotten more incident reviews than I remember.
There are a few common themes in managing production infrastructure:
How do I determine what happened?
What just happened?
When I push a button, will it do the thing I want?
On my first week working at AOL over two decades ago, I was asked to change the parental control system, RATS.
I was terrified.
My mentor Valerie told me, “Deploy this new configuration to the RATS and ensure it works.”
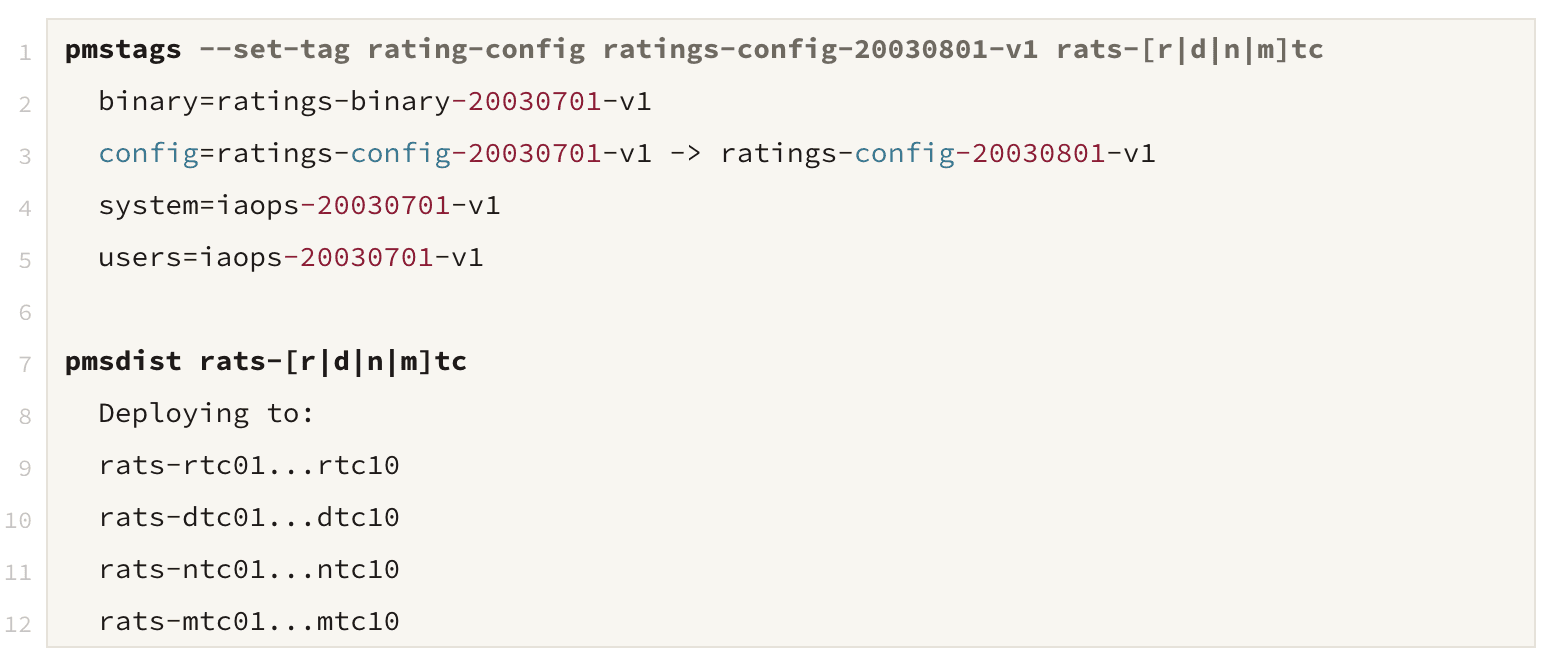
(These commands set the configuration on the RATS servers in the RTC, DTC, NTC, and MTC datacenters and distribute code to them — effectively a kubectl -f apply deployment.yaml or updating a GitOps docker hash and waiting for it to be synced.)
I did not know if this change would work, what was happening under the hood, or how to triage if it went wrong. I felt powerless, like Tobey Maguire Spiderman in Spiderman 2 losing his powers.

I lacked complete situational awareness that only Valerie, an industry veteran and previous owner of the RATS system, had.
Over the next five years, I developed my own Spidey Sense and became a senior engineer. I was trusted with deploying and scaling infrastructure globally for millions of AOL users.
I went through the same journey developing a Spidey Sense tuned to YouTube and later Dropbox.
Now, after seeing three eras of the internet, helping deploy and debug thousands of issues, and advising startups and enterprises on infrastructure, the pattern for developing a Spidey Sense has not changed.
What has changed is the time it takes to understand today’s complex systems, which just keeps increasing.
Does it have to be that way?
Unboxing The Spidey Sense
The Spidey Sense is a personal and internal algorithm senior engineers run that is built over time. After talking to senior engineers, it's clear the algorithm operates on the same principles for all of them.
It uses environmental context and change(s) as input and generates a score as an output. This is applied recursively until stop conditions are met, such as “time spent exploring an area,” “likely commit or change is found,” or “lack of new information try from the root again.”
This straightforward algorithm is applied pre and post-deployment every day by the superheros who troubleshoot systems.
As the inputs and stop conditions show, the complexity is understanding what signals are needed, when they are used, and how to score them.
Clairvoyance: Your Personal Spidey Sense.
Prodvana has solved this problem with Clairvoyance, your personal spidey sense.
Access to the “What Changed” is now possible through AI’s LLMs, infrastructure that is now API-first, and more standardized building blocks delivered from Cloud Service Providers.
We can filter, sift, and categorize massive amounts of context, previously called “on-the-job experience.”
The “When” and “How” are enabled through our expertise at Prodvana.
We have analyzed the thought process senior engineers take in triaging, debugging and, building out mechanisms to catalog releases and codified this into Clairvoyance.
Ultimately, Clairvoyance analyzes a release and the changes within that release. It does this by taking the same basic framework senior engineers use.
The following examples show how this works on the Sentry and Prodvana’s codebases for scoring.
We’ve applied the internal filter I personally use. My first two thoughts are, “What area and what type of issue might this change induce?”
I then apply a filter to drop everything that looks “normal.” In this case, we’re filtering risks => 4 (things that look abnormal) on a scale of 1-9 over the last 300 changes.
Sentry
Here, Clairvoyance has helped us look at the Sentry code base. We can see a hazardous change with a score of 9 out of 9, which could cause an outage.
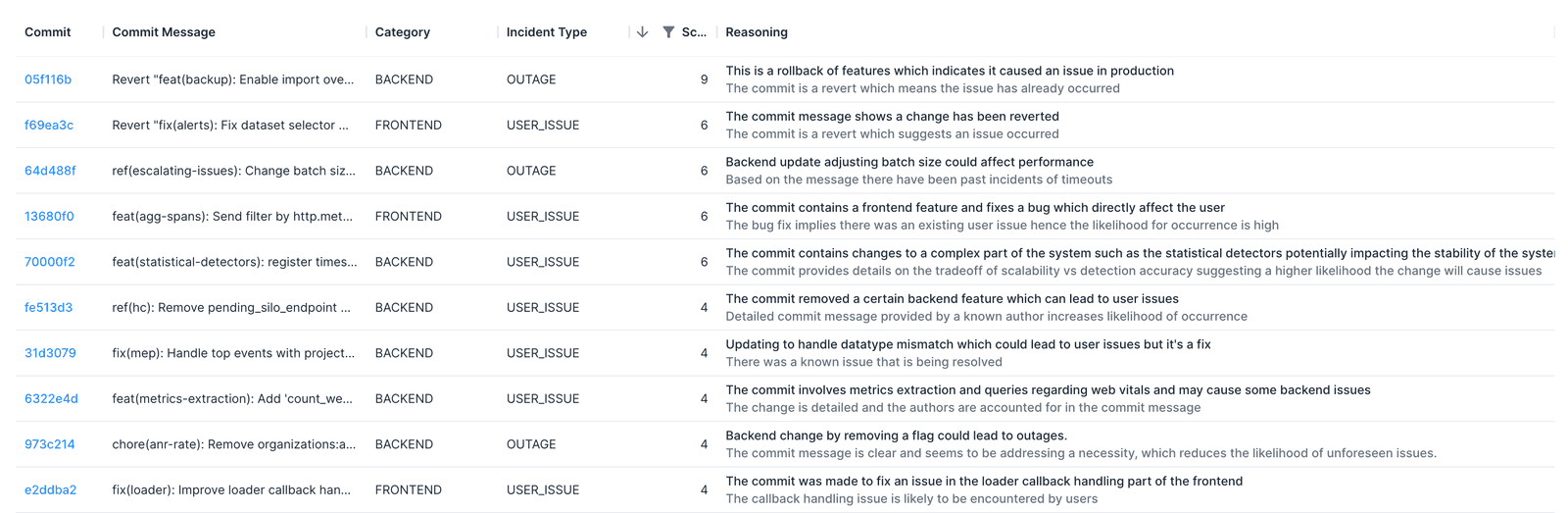
If we look at the reverted change, we see that this was about reverting a change that allowed importing over RPC — quite a dangerous change. If someone was using the import system in the client and then the backend reverted it, that would indeed cause an outage!
Prodvana
In this example, we are using Clairvoyance to examine Prodvana's own code.

Looking at commit 7fd6ea, we can see a commit about scaling out the system and making data model changes to increase scalability. Scoring this at a risk of 5 makes sense since the functionality is supposedly not changing, but it's a good starting point to be on the lookout for quirky behavior.
Clairvoyance In Practice
With Clairvoyance, get the power to examine what release is where, who deployed it, what system deployed the release, and the information around high-impact commits, all through an interface that feels like git log, making it easy for any engineer to pick up.
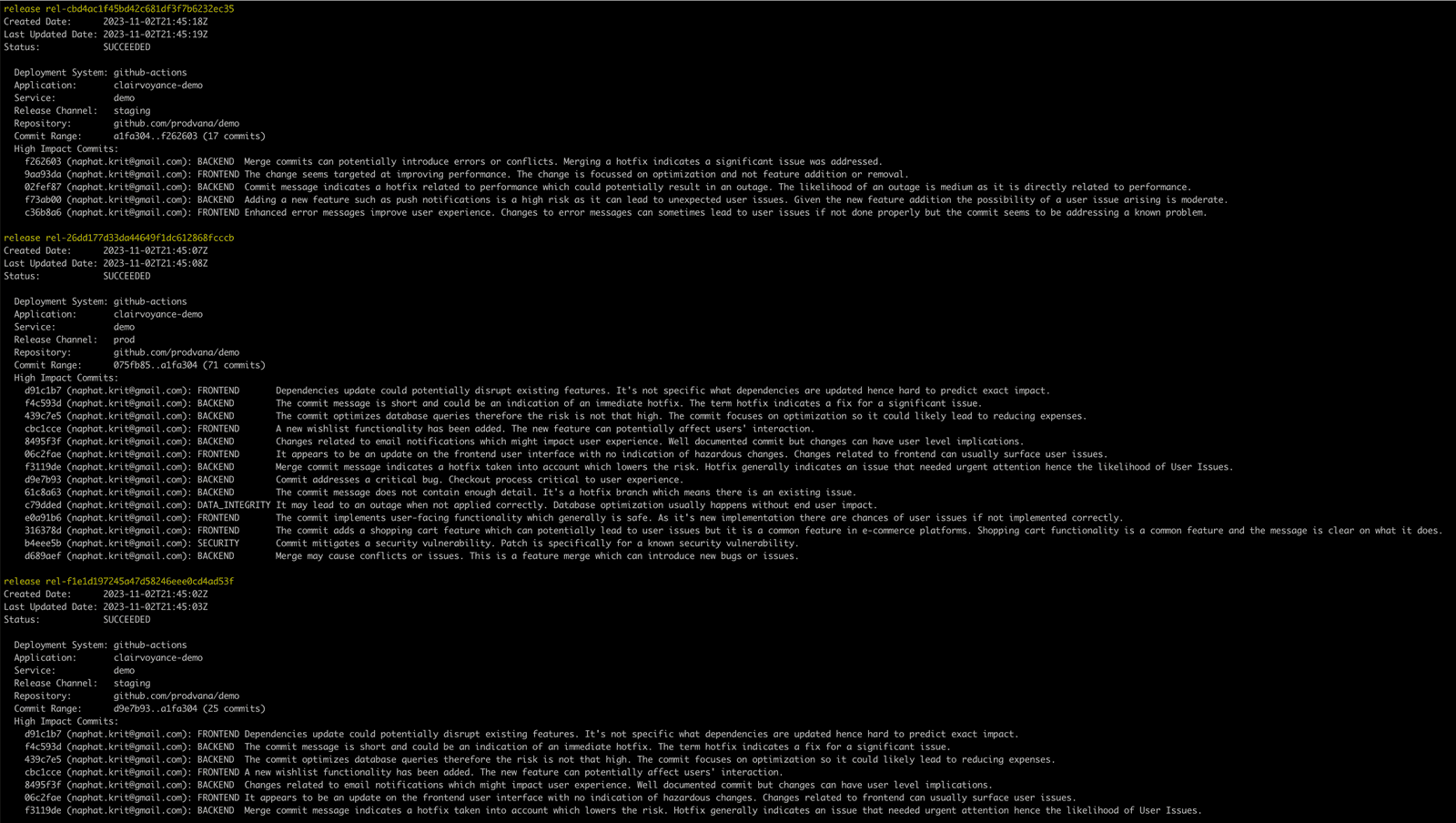
Adopting Clairvoyance
Clairvoyance, honed on experiences across companies like Google, Dropbox, Facebook, WeWork, YouTube, Grooveshark, and Compass, is available today.
To get started add a GitHub Action to your release flow. Prodvana captures a release and calculates the likely impacted areas such as backend, frontent, or data integrity the changes associated with the area, and expected impact of the the changes.
For current Prodvana users Clairvoyance will bring this context into the Application Engineer's sidebar right in line with your deployment workflow flow.
Get Clairvoyance to continue to shift operations left!
Meet the team in Discord!






